인덱스란?
인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상하기 위한 자료구조이다.
DB 내 저장된 데이터가 저장된 주소를 가지고 있어 데이터를 조회할 때 결과를 빠르게 추출하도록 도와준다.
책의 색인에 대한 특징들을 나열하며 인덱스를 설명한 블로그를 봤는데 개념이 확 와닿아서 해당 내용을 참고해서 기록해보려고 한다.
참고: https://jeong-pro.tistory.com/242
두꺼운 책을 보면 특정 내용이 몇 페이지에 있는지 확인 가능한 색인 페이지가 있다.
데이터베이스의 인덱스는 책의 색인과 비슷하다.
위 블로그에서 설명해 주신 책의 찾아보기(색인)가 가지고 있는 특징들은 아래와 같다.
- 책에 있는 모든 용어가 아닌 자주 찾아보는 핵심 용어만 간추려 정리한다.
- 알파벳 또는 한글 순서 등으로 정렬되어 있다.
- 간단하게 용어에 대한 내용이 나와있는 페이지 번호만 제공한다.
- 색인 페이지가 전체 분량의 2~30% 이상이라면 그냥 전체 페이지를 뒤져 찾는 게 빠를 수 있기에 색인 페이지는 적절한 비율로 제공한다.
- 너무 여러 곳에 등장하는 용어는 색인에 나타내지 않는다.
데이터베이스의 인덱스가 가지는 특징들은 아래와 같다.
- 모든 칼럼에 인덱스를 추가하는 것이 아니라 조회 시에 자주 사용되는 칼럼들에 한해 인덱스를 추가한다.
- 인덱스는 항상 정렬된 상태를 유지한다.
- 인덱스는 직접적으로 데이터를 가지고 있는 것이 아니라 데이터가 저장된 주소를 가진다.
- 읽어야 할 레코드의 건수가 전체 테이블 레코드의 20~25%를 넘어서면 인덱스를 이용하지 않는 것이 효율적이다.
- 카디널리티가 높을수록(= 한 칼럼이 가지고 있는 중복의 정도가 낮을수록) 인덱스 추가하기에 적절하다.
비교하여 확인해 보니 데이터베이스의 인덱스의 특징과 굉장히 유사하다는 것을 알 수 있다.
즉, 인덱스는 데이터베이스에서 색인과 같은 역할을 하며 데이터의 저장 성능을 희생하지만 검색 속도 향상에 도움을 준다.
장단점
- 장점
- 적절한 인덱스를 생성하고 사용하면 조회 성능을 획기적으로 개선할 수 있음 (검색 속도 향상 & 시스템 성능 향상)
- 단점
- 추가 저장 공간 필요
- SELECT 가 아닌 데이터의 변경 작업(INSERT, UPDATE, DELETE)이 자주 일어나면 오히려 성능에 악영향을 미칠 수 있음
MySQL의 인덱스 자료구조
DBMS마다 B-Tree 알고리즘, Hash 인덱스 알고리즘 등 인덱스 데이터 저장 방식이 다양하지만
이 글에서는 MySQL의 인덱스 데이터 저장 방식에 대해서 알아보려고 한다.
아래 명령어를 통해 테이블의 스토리지 엔진을 확인해 볼 수 있다.
SHOW TABLE STATUS WHERE name='users';
MySQL의 기본 데이터베이스 엔진인 InnoDB의 인덱스는 B+Tree 구조를 기반으로 한다.
| 엔진 | 인덱스 자료구조 | 엔진 특징 |
| MyISAM | B-tree | 트랜잭션을 지원하지 않고, Table 단위의 Locking입니다. 따라서, 다수개의 세션이 동시에 작업하는 경우 성능이 저하될 수 있습니다. |
| InnoDB | B+tree | MySQL에서 기본으로 설정되는 엔진이며 일반적인 DBMS 기능을 지원합니다. |
| Archive | X | Archive는 로그 수집에 적합한 엔진으로 데이터가 메모리상에서 압축된 후, 압축된 상태로 디스크에 저장됩니다. 한번 Insert 된 데이터는 Update나 Delete를 할 수 없으며, 인덱스를 지원하지 않기 때문에 인덱스 자료구조가 없습니다. |
출처: https://ledpear.tistory.com/56
B+Tree 인덱스
B+Tree는 B-Tree의 확장된 개념이다.
B+Tree에 대해 알아보기 전에 B-Tree에 대해 알아보자.
B-Tree
우선, 트리의 기본적인 구조는 아래와 같다.
- 루트 노드
- 트리 구조의 최상위에 있는 노드로, 하위에 자식 노드가 붙어 있다.
- 브랜치 노드
- 루트 노드도 아니고, 리트 노드도 아닌 중간의 노드를 뜻한다.
- 리프 노드
- 트리 구조의 가장 하위에 있는 노드를 뜻한다.
B-Tree는 이진트리에서 확장되어 모든 리프 노드들이 같은 레벨을 가질 수 있도록 삽입/삭제가 일어나더라도 자동으로 밸런스를 맞추는 트리 구조이다.
그렇기에 B-Tree의 B는 Binary가 아닌 Balanced를 의미한다고 볼 수 있다.
이진트리와 다르게 하나의 노드에 2개 이상의 자료가 들어갈 수 있고 항상 정렬된 상태로 저장된다.
최대 3개의 자료를 가질 수 있다고 정의하면, 최대 자식 노드 수는 3+1=4개가 되고 이러한 B-tree를 4차 B-tree라고 부른다.
즉, 최대 N개의 자식을 가질 수 있는 B트리를 N차 B트리라고 하며 아래와 같은 특징들을 가진다.
- N차 B 트리는 노드의 최대 자료수는 N-1이며, 자식노드는 최대 N개.
- 노드의 자료가 최대 N개 라면, 해당 노드의 자식 노드 개수는 항상 N+1.
- 노드의 자료가 최대 N개 라면, 노드의 자료 개수는 [N/2] ~ N개. (루트 노드 제외)
- 모든 리프 노드들은 항상 같은 레벨에 위치한다.
인덱스에 대해 다루는 글이기에, B-Tree의 자세한 특징 설명과 삽입/삭제 과정에 대한 내용은 다음에 알아보도록 하고 하자.
B-Tree와 B+Tree의 차이점
B+Tree는 B-Tree의 확장 개념이다.
대신 B-Tree와 다르게 리프 노드에만 데이터가 저장되고 리프 노드끼리는 Linked List로 연결되어 있다.
Linked List로 연결되어 있어 B-Tree에 비해 순차 검색이 용이하다는 장점과
모든 경우에도 무조건 리프 노드까지 가야 한다는 단점이 있다.
B+Tree 인덱스의 각 노드와 데이터 파일의 관계를 표현한 그림이다.
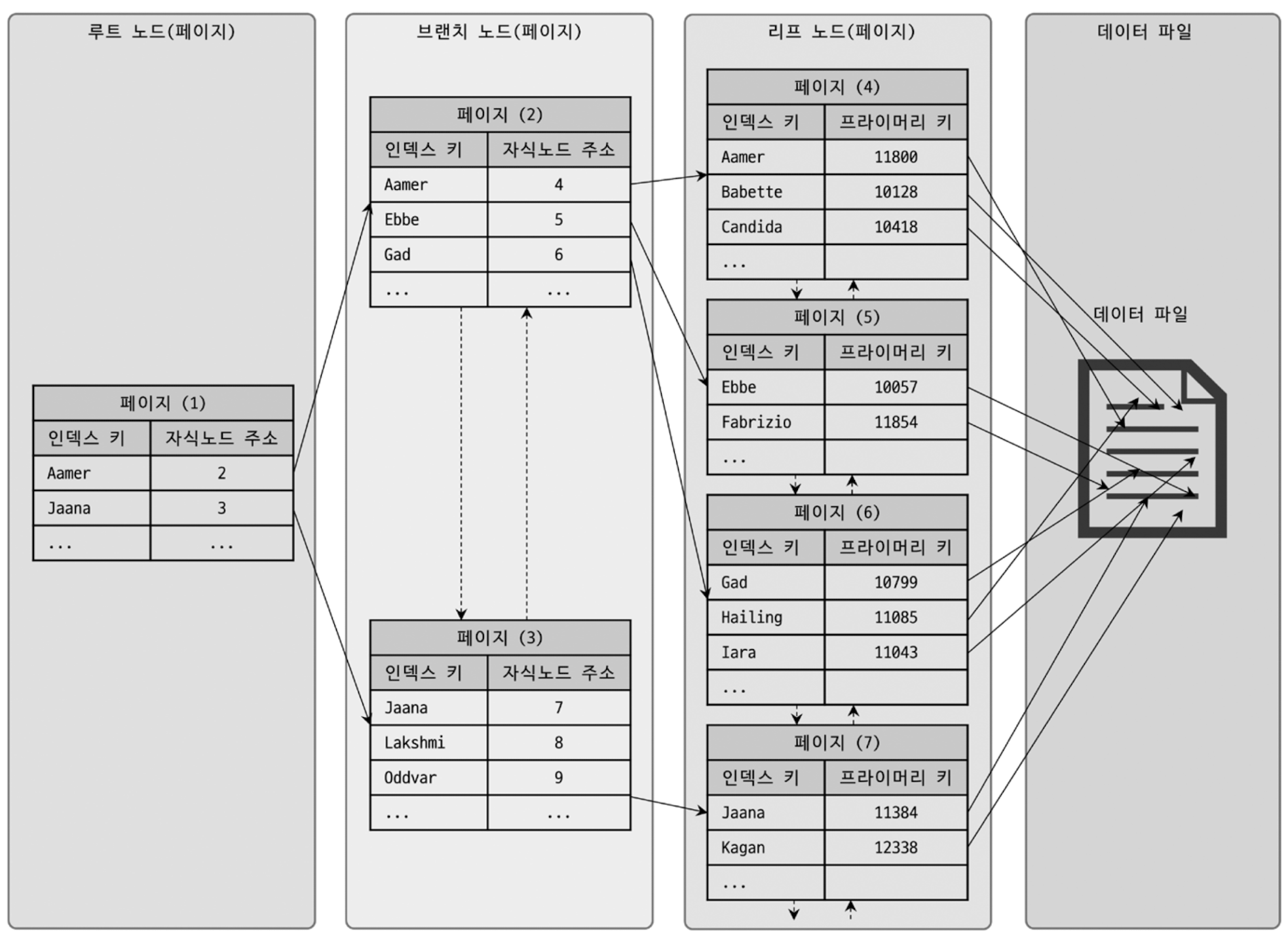
인덱스는 테이블의 키 칼럼만 가지고 있기 때문에, 나머지 칼럼들을 읽으려면 데이터 파일에서 해당 레코드를 찾아야 한다.
이 과정에서 스토리지 엔진별로 차이점이 있다.
MyISAM 테이블은 세컨더리 인덱스가 데이터의 물리적인 주소를 가지고,
InnoDB 테이블은 프라이머리 키를 주소처럼 사용하기 때문에 논리적인 주소를 가진다고 볼 수 있다.
(* 세컨더리 인덱스: 프라이머리 키를 제외한 나머지 모든 인덱스)
즉, InnoDB 스토리지 엔진에서는 모든 세컨더리 인덱스 검색에서 데이터 레코드를 읽기 위해서는 반드시 프라이머리 키를 저장하고 있는 B-Tree를 다시 한번 검색해야 한다.
<참고>
https://mangkyu.tistory.com/96
https://velog.io/@sem/DB-인덱스-자료-구조-B-Tree